以下记条件概率 P(A∣B) 为 PB(A)
# 假设检验
在统计中,通过实际的统计计算对现实中的问题进行推断,称为检验。
简单来说,检验是指基于一系列数据,判断是否可以足以拒绝某个主张的流程
在统计检验的过程中,第一步是针对具体问题设定两个假设
- 原假设 (Null Hypothesis)「帰無仮説」 H0:通常是我们想要反驳的假设
- 备择假设 (Alternative Hypothesis)「対立仮説」 H1:通常是我们想要证明的假设
通常来说,原假设的形式是:【没有差别】,【没有效果】
- 例如总体平均 μ=100
备择假设的形式是:【有差别】,【有效果】
- 例如总体平均 μ=100, μ<100, μ>100
例如,某饮料标称 500ml,抽样调查其样品数据后,想要检验是否可以认为该饮料容量确实为 500ml
则可以设定
- 原假设 H0:μ=500
- 备择假设 H1:μ=500
统计检验的过程宏观上的原理为反证法
- 假设原假设 H0 为真
- 计算某个 检验统计量 (Test Statistic)「検定統計量」 T
- 根据中心极限定理,可以得到统计检验量 T 应该服从某个已知的分布
- 取该分布中,概率 α 的极端区域 Rα 作为 拒绝域 (Rejection Region)「棄却域」
,即:
PH0(T∈Rα)=α
- 基于样本数据,计算出观测到的统计检验量 tobs
- 此时的逻辑是:“如果 H0 是真的,那么观测到的统计量是不应该落在拒绝域内的”
- 此时如果 tobs∈Rα,也就是落在拒绝域,这等于在说 H0 不为真,于是拒绝 H0,接受 H1
- 而如果 tobs∈/Rα,则无法拒绝 H0(请注意我这里的用词是 “无法拒绝” 而不是 “接受”,这是因为逻辑上这并不是在说我们得到了 H0 为真的结果,只是基于现有的数据,我们无法证伪 H0)
实际上,由于样本的选取是随机的,其可以反应大部分的总体性质但不能确保一定百分百反应总体性质,也就是说需要明确:统计检验存在错误概率
通常,在统计检验前,需要选取 显著性水平 (Significance Level)「有意水準」 α,其表示在原假设 H0 为真的情况下,错误地拒绝 H0 的概率
例如,α=0.05 表示有 5% 的概率会错误地拒绝原假设 H0
显著性水平也被称为危险率
原假设可能为真,也可能为假,统计检验的结论也存在拒绝与不拒绝两种可能
所以统计检验出错的情况也有两种,见下表
| 实际情况 \ 检验结论 |
拒绝 H0 |
不拒绝 H0 |
| H0 为真 |
第一类错误 (Type I Error) |
正确结论 |
| H0 为假 |
正确结论 |
第二类错误 (Type II Error) |
两类错误
- 第一类错误 (Type I Error)「第一種の誤り」:在原假设为 真 的情况下,错误地 拒绝 了原假设 H0。
- 第二类错误 (Type II Error)「第二種の誤り」:在原假设为 假 的情况下,错误地 不拒绝 了原假设 H0。
通常情况 下,第一类错误的概率为显著性水平 α
但是对于部分离散的分布,有可能会得到实际的第一类错误概率小于显著性水平 α 的情况
所以唯一能确定的是
P(第一类错误)≤α
第二类错误的概率记作 β,实际上 β 通常难以计算
称 1−β 为检验的 效能 (Power)「検出力」,表示在 H0 为假的情况下,正确地拒绝 H0 的概率
以下示例给出第一类错误概率不为显著性水平 α 的情况
示例
现有两种分布
分布 A:
| X |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| P |
0.15 |
0.25 |
0.2 |
0.15 |
0.1 |
0.1 |
0.05 |
分布 B:
| X |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
| P |
0.05 |
0.1 |
0.15 |
0.2 |
0.2 |
0.2 |
0.1 |
设定
- 原假设 H0: 样本来自分布 A
- 备择假设 H1: 样本来自分布 B
拒绝域设为 X≥5,求第一类错误概率,第二类错误概率,检验效能
以及在显著性水平 α=0.07 下,第一类错误概率
解
第一类错误概率
P(X≥5∣H0)=0.1+0.1+0.05=0.25
第二类错误概率
P(X<5∣H1)=0.05+0.1+0.15+0.2=0.5
检验效能
1−β=1−0.5=0.5
接下来考虑显著性水平 α=0.07 下的情况
此时由于
P(X≥6)=0.15>0.07,P(X≥7)=0.05≤0.07
所以拒绝域应设为 X≥7
此时第一类错误概率为
P(X≥7∣H0)=0.05<0.07
在经过一系列计算后,往往可以得出检验的结果
检验结果基于显著性水平与假设,注意核心的流程是在于判断 是否要拒绝原假设
所以检验结论通常有两种形式
- 在显著性水平 α 下,拒绝原假设 H0,接受备择假设 H1
- 在显著性水平 α 下,无法拒绝原假设 H0,无法接受备择假设 H1
# 拒绝域的选取
针对给定的容错,也就是显著性水平 α
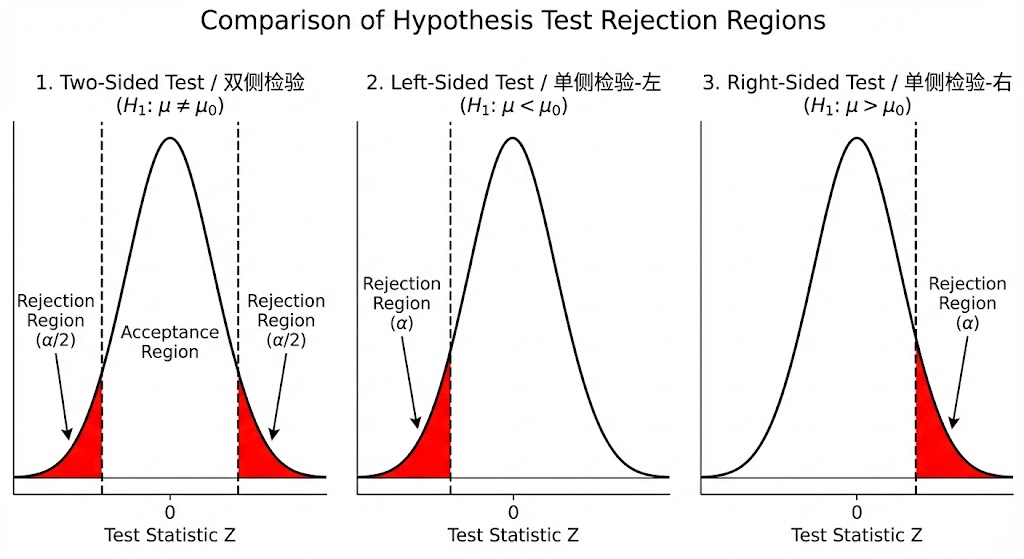
我们已经明确:拒绝域是 “统计量不应该落入的极端区域”。一旦统计量落入,我们就可以得出拒绝原假设的结论。
但是此时依据对立假说的形式,结论会有所不同。当对立假设为 H1:μ=μ0 时,为了使得落入拒绝域等价于可以接受 H1,拒绝域的设定应该是两侧对称的。
而当对立假说的形式类似为 H1:μ>μ0 时,你会发现:即使统计量处于非常极端的,分布的左侧区域,但是此时我们也无法接受 H1,因为 H1 只关心右侧区域。这使得拒绝域的设定应该完全位于右侧
![拒绝域的选取]()
也就是说,拒绝域的判断依赖于备择假设,存在两种情况,注意两种情况下原假设都一致 H0:μ=μ0
- 两侧检验 (Two-tailed Test)「両側検定」:备择假设形式为 H1:μ=μ0,此时拒绝域为统计量 T 落在两侧极端区域
- 单侧检验 (One-tailed Test)「片側検定」:备择假设形式为 H1:μ>μ0 或 H1:μ<μ0,此时拒绝域为统计量 T 落在一侧极端区域
另外一种可行的方案是 p 值法
p 值法的核心在于,针对统计量 T,计算出
p:=PH0(得到比观测值更极端的结果)
换言之,p 值描绘了:该结果在 H0 为真的情况下有多么难以发生,
p≤α⟺T∈Rα
同时,p 值也是 “拒绝所需的最小显著性水平”
- 如果 p≤α,则拒绝原假设 H0(结果显著)
- 如果 p>α,则不拒绝原假设 H0(结果不显著)
p 值法的计算同样依赖于备择假设的形式,设 T∼N(0,1),观测值为 tobs,则
- 对于两侧检验 H1:μ=μ0,p 值计算为
p=PH0(∣T∣≥∣tobs∣)=2PH0(T≥∣tobs∣)
- 对于右单侧检验 H1:μ>μ0,p 值计算为
p=PH0(T≥tobs)
- 对于左单侧检验 H1:μ<μ0,p 值计算为
p=PH0(T≤tobs)
Excel 中的计算
Excel 中存在函数 NORMDIST(|Z|,0,1,TRUE) 用于计算标准正态分布的累积分布函数,即返回 P(T≤∣Z∣)
那么 1 - NORMDIST(|Z|,0,1,TRUE) 则返回 P(T≥∣Z∣)
由此也可以得到两侧检验中的 p 值计算公式: 2 * (1 - NORMDIST(|Z|,0,1,TRUE))
# 常见统计检验
本节给出各类常见的统计检验示例
总结:
- 涉及到总体均值的检验:
- 已知总体方差时,使用正态分布
- 未知总体方差时,使用 t 分布
- 涉及到总体方差的检验,使用 χ2 分布
- 涉及到总体比例的检验,使用正态分布
# 总体均值检验
例题 已知总体方差的总体均值两侧检验
某饮料标称 500ml,现取 36 瓶测得平均容量为 498.5ml
已知总体方差为 9ml2
问在显著性水平 0.05 下,能否说该饮料容量确实如标称的 500ml?
解
设定参量
样本量 n=36
样本平均 X=498.5
总体方差 σ2=9
宣称平均 μ0=500
显著性水平 α=0.05 (两侧)
原假设 H0:μ=500
备择假设 H1:μ=500
计算检验统计量
Z=σ/nX−μ0=3/6498.5−500=−3
在 α=0.05 下,z(α/2)=1.960
由于 ∣Z∣=3>1.960,落在拒绝域内
所以拒绝原假设 H0,接受备择假设 H1
结论:在显著性水平 0.05 下,能说该饮料容量确实不如标称的 500ml
例题 已知总体方差的总体均值单侧检验
某饮料标称 500ml,现取 36 瓶测得平均容量为 498.5ml
已知总体方差为 9ml2
问在显著性水平 0.05 下,能否说该饮料容量确实大于 500ml?
解
设定参量
样本量 n=36
样本平均 X=498.5
总体方差 σ2=9
宣称平均 μ0=500
显著性水平 α=0.05 (单侧)
原假设 H0:μ≤500
备择假设 H1:μ>500
计算检验统计量
Z=σ/nX−μ0=3/6498.5−500=−3
在 α=0.05 下,z(α)=1.645
由于 Z=−3<1.645,不落在拒绝域内
所以不拒绝原假设 H0,无法接受备择假设 H1
结论:在显著性水平 0.05 下,不能说该饮料容量确实大于 500ml
例题 未知总体方差的总体均值检验
随机抽取某碳酸饮料 12 瓶,测得其砂糖含量(单位 g/L)如下
9.6,10.1,10.4,9.8,11.2,10.5,9.9,10.3,10.7,9.5,10.0,10.6
问在显著性水平 0.05 下,能否说该碳酸饮料的砂糖含量确实如标称的 10 g/L?
解
设定参量
- 样本量 n=12
- 样本平均 X=10.2167
- 宣称平均 μ0=10
- 显著性水平 α=0.05 (两侧)
假设
- 原假设 H0:μ=10
- 备择假设 H1:μ=10
计算样本无偏方差
S2=n−11i=1∑12(Xi−X)2=0.245
计算检验统计量
T=S/nX−μ0=0.245/1210.2167−10≈1.52
在 α=0.05 下,查 t 分布表可得
t11(0.025)=2.201
由于 ∣T∣≈1.52<2.201,不落在拒绝域内
所以不拒绝原假设 H0,无法接受备择假设 H1
结论:在显著性水平 0.05 下,不能说该碳酸饮料的砂糖含量确实如标称的 10 g/L
# 总体方差检验
例题 已知总体平均的总体方差检验
某产品的重量服从正态分布,总体平均已知为 50g
现随机抽取 25 件产品,测得差值平方和
Q=i=1∑25(Xi−50)2=720
问在显著性水平 0.05 下,能否说该产品的重量方差不同于 25g2?
解
设定参量
- 样本量 n=25
- 差值平方和 Q=720
- 宣称方差 σ02=25
- 显著性水平 α=0.05 (两侧)
假设
- 原假设 H0:σ2=25
- 备择假设 H1:σ2=25
计算检验统计量
χ2=σ02Q=25720=28.8
自由度 25
在 α=0.05 下,查卡方分布表可得
χ252(0.025)=13.1,χ252(0.975)=40.7
由于 χ2=28.8 不落在拒绝域内
所以不拒绝原假设 H0,无法接受备择假设 H1
结论:在显著性水平 0.05 下,不能说该产品的重量方差不同于 25g2
例题 未知总体平均的总体方差检验
随机抽取某饮料 10 瓶,测得咖啡因浓度(单位 mg/L)如下
58,63,61,60,59,62,57,64,60,61
问在显著性水平 0.05 下,能否说该饮料的咖啡因浓度方差不同于 9(mg/L)2?
解
设定参量
- 样本量 n=10
- 样本数据 58,63,61,60,59,62,57,64,60,61
- 宣称方差 σ02=9
- 显著性水平 α=0.05 (两侧)
假设
- 原假设 H0:σ2=9
- 备择假设 H1:σ2=9
计算样本均值
X=1058+63+61+60+59+62+57+64+60+61=60.5
计算平方和
Q=i=1∑10(Xi−X)2=(58−60.5)2+(63−60.5)2+⋯+(61−60.5)2=42.5
计算卡方统计量
χ2=σ02Q=942.5≈4.7222
自由度 10−1=9
在 α=0.05 下,查卡方分布表可得
χ92(0.025)=2.7,χ92(0.975)=19.0
由于 χ2=4.7222 不落在拒绝域内
所以不拒绝原假设 H0,无法接受备择假设 H1
结论:在显著性水平 0.05 下,不能说该饮料的咖啡因浓度方差不同于 9(mg/L)2
# 总体比例检验
例题 已知总体方差的总体比例单侧检验
某工厂生产的产品不合格率宣称为 2
现随机抽取 400 件产品,发现其中有 14 件不合格
问在显著性水平 0.05 下,能否说该工厂生产的产品不合格率确实大于 2?
解
设定参量
- 样本量 n=400
- 样本不合格数 X=14
- 样本比例 p^=nX=40014=0.035
- 宣称比例 p0=0.02
- 显著性水平 α=0.05 (单侧)
假设
- 原假设 H0:p=0.02
- 备择假设 H1:p>0.02
计算检验统计量
Z=np0(1−p0)p^−p0=4000.02×0.980.035−0.02≈2.143
在 α=0.05 下,z(α)=1.645
由于 Z≈2.143>1.645,落在拒绝域内
所以拒绝原假设 H0,接受备择假设 H1
结论:在显著性水平 0.05 下,能说该工厂生产的产品不合格率确实大于 2
# 两样本问题:总体均值差值检验
例题 已知总体方差的总体均值差值检验
某饮料同时由 A,B 两家工厂生产,两家工厂生产的标准差均为 3ml
现从 A 工厂随机抽取 36 瓶,测得平均容量为 498.5ml
从 B 工厂随机抽取 36 瓶,测得平均容量为 500.4ml
问在显著性水平 0.05 下,能否说两家工厂生产的饮料容量存在差异?
解
设定参量
- 样本量 n1=36,n2=36
- 样本平均 X=498.5,Y=500.4
- 总体方差 σ12=9,σ22=9
- 显著性水平 α=0.05 (两侧)
假设
- 原假设 H0:μ1=μ2
- 备择假设 H1:μ1=μ2
计算检验统计量
Z=n1σ12+n2σ22(X−Y)−0=369+369(498.5−500.4)−0=−2.69
在 α=0.05 下,z(α/2)=1.960
由于 ∣Z∣=2.69>1.960,落在拒绝域内
所以拒绝原假设 H0,接受备择假设 H1
结论:在显著性水平 0.05 下,能说两家工厂生产的饮料容量存在差异
例题 等方差下的总体均值差值检验
某药品分别由传统方法 B 与新方法 A 生产
现从 A 方法中随机抽取 10 件样品,测得其有效成分含量(单位 mg)如下
100.8,100.5,100.6,100.7,100.4,100.2,100.5,100.6,100.3,100.8
从 B 方法中随机抽取 10 件样品,测得其有效成分含量(单位 mg)如下
99.6,99.8,99.7,99.9,100.0,99.5,99.7,99.8,99.6,99.8
问在显著性水平 0.05 下,能否说两种方法生产的药品有效成分含量存在差异?
解
设定参量
- 样本量 n1=10,n2=10
- 样本平均 X=100.54,Y=99.74
- 样本方差 S12=0.0404,S22=0.0227
- 显著性水平 α=0.05 (两侧)
假设
- 原假设 H0:μ1=μ2
- 备择假设 H1:μ1=μ2
计算合并方差
Sp2=n1+n2−2(n1−1)S12+(n2−1)S22=189×0.0404+9×0.0227=0.03156
计算检验统计量
T=Spn11+n21(X−Y)−0=0.03156101+101(100.54−99.74)−0≈10.07
自由度 n1+n2−2=18
在 α=0.05 下,查 t 分布表可得
t18(0.025)=2.101
由于 ∣T∣≈10.07>2.101,落在拒绝域内
所以拒绝原假设 H0,接受备择假设 H1
结论:在显著性水平 0.05 下,能说两种方法生产的药品有效成分含量存在差异
# 两样本问题:总体比例差值检验
# 适合度检验与独立性检验
相较于前面对于统计量计算的检验,适合度检验与独立性检验更多地用于分类数据
适合度检验是给出一个具体的分布,通过统计检验判断样本数据是否服从该分布
独立性检验是给出两个分类变量,通过统计检验判断这两个变量是否独立
命题
对于任意 k≥2 与变量 y1,y2,…,yk,
(y1+y2+⋯+yk)2=r1+r2+⋯+rk=n∑r1!r2!⋯rk!n!y1r1y2r2⋯ykrk
例题 适合度检验
有某理论宣传血型分布为
p(0)=(A:0.4, B:0.3, AB:0.2, O:0.1)
现随机抽取 150 人,测得血型分布为
| 血型 |
A |
B |
AB |
O |
总计 |
| 人数 |
64 |
41 |
33 |
12 |
150 |
问在显著性水平 0.05 下,能否说该样本数据服从上述血型分布?
解
设定参量
- 样本量 n=150
- 样本数据见上表
- 宣称分布 p(0)=(0.4,0.3,0.2,0.1)
- 显著性水平 α=0.05 (两侧)
假设
- 原假设 H0: 该样本数据服从上述血型分布
- 备择假设 H1: 该样本数据不服从上述血型分布
计算期望频数
| 血型 |
A |
B |
AB |
O |
总计 |
| 期望频数 |
60 |
45 |
30 |
15 |
150 |
计算检验统计量
χ2=∑Ei(Oi−Ei)2=1.63
自由度 k−1=4−1=3
在 α=0.05 下,查卡方分布表可得
χ32(0.95)=7.815
由于 χ2=1.63 不落在拒绝域内
所以不拒绝原假设 H0,无法接受备择假设 H1
结论:在显著性水平 0.05 下,不能说该样本数据不服从上述血型分布
例题 独立性检验
通过对 206 名大学生抽样调查 【性别】 与 【喜欢的季节】 之间的关系,得到如下数据
| 性别 \ 季节 |
春 |
夏 |
秋 |
冬 |
总计 |
| 男 |
20 |
32 |
24 |
28 |
104 |
| 女 |
28 |
34 |
20 |
20 |
102 |
| 总计 |
48 |
66 |
44 |
48 |
206 |
问在显著性水平 0.05 下,能否说【性别】 与 【喜欢的季节】 存在关联?
解
设定参量
- 样本量 n=206
- 样本数据见上表
- 显著性水平 α=0.05 (两侧)
假设
- 原假设 H0: 【性别】 与 【喜欢的季节】 独立
- 备择假设 H1: 【性别】 与 【喜欢的季节】 不独立
计算期望频数 E_{ij} = \frac{\text{行和}_i \times \text{列和}_j}
| 性别 \ 季节 |
春 |
夏 |
秋 |
冬 |
| 男 |
24.23 |
33.32 |
22.21 |
24.23 |
| 女 |
23.77 |
32.68 |
21.79 |
23.77 |
计算检验统计量
χ2=∑Ei(Oi−Ei)2≈3.08
自由度 (r−1)(c−1)=(2−1)(4−1)=3
在 α=0.05 下,查卡方分布表可得
χ32(0.95)=7.815
由于 χ2≈3.08 不落在拒绝域内
所以不拒绝原假设 H0,无法接受备择假设 H1
结论:在显著性水平 0.05 下,不能说【性别】 与 【喜欢的季节】 存在关联
# 检验效能
固定显著性水平 α
考虑:究竟哪一种检验可以使得第二类错误概率 β 最小化
先来关注针对 z 检验的这样的例子
给定显著性水平 α,以及 n 个服从正态分布 N(μ,σ2) 的样本
- 原假设 H0:μ=μ0
- 备择假设 H1:μ=μ0
计算出统计量
Z=σ/nX−μ0∼N(0,1)
现在可以知道,如果原假设 H0 成立,那么
Z∼N(0,1)
如果备择假设 H1 成立,那么由于 X∼N(μ′,σ2/n),其中 μ′ 为真实的总体平均,那么
Z∼N(δ,1),δ=σ/nμ′−μ0
那么,可以分别算出第一,第二类的错误概率
P(第一类错误)=P(拒绝 H0∣H0 成立)=P(∣Z∣≥z(α)∣Z∼N(0,1))=α
β(μ):=P(第二类错误)=P(不拒绝 H0∣H1 成立)=P(−z(α)≤Z≤z(α)∣Z∼N(δ,1))=∫−z(α)z(α)2π1exp(−2(z−δ)2)dz=∫−z(α)−δz(α)−δ2π1exp(−2u2)du
检验效能
π(μ)=1−β(μ)=∫∣z∣≥z(α)−δ2π1exp(−2z2)dz
可以看出,如果缩小显著性水平 α,则 z(α) 会增大,从而使得区间
[−z(α)−δ, z(α)−δ]
变大,那么结果上
第二类错误概率 β(μ)↑,检验效能 π(μ)↓
简单来说,减小显著性水平 α 会导致第二类错误概率增大,检验效能降低
同样可以得到,如果增大样本量 n,
第二类错误概率 β(μ)↓,检验效能 π(μ)↑
如果增加宣称平均 μ0 与真实平均 μ′ 之间的差距 ∣μ′−μ0∣,
第二类错误概率 β(μ)↓,检验效能 π(μ)↑
内容已经过 Gemini 3.0 Pro 审查